Over the past few months, we have been refining our domain name segmentation pipeline, experimenting with a variety of models to split domain strings into meaningful words. During this process, as we tried using LLMs to directly segment domains, we realized that this approach might not fully leverage the knowledge these models acquired during pre-training.
This led to a key insight: instead of asking LLMs to generate segmentations, we should train them to select the best result from a set of candidates. That way, the model’s pre-trained knowledge of words, brands, and languages can actually come into play.
We integrated our existing segmentation models into a unified pipeline built around DKSplit. Under this hybrid architecture, we narrowed the output to a top-5 candidate list. On our benchmark of 5,000 domains, the oracle accuracy of these top-5 candidates reached 99.5% (4,974/5,000). This dataset became the foundation for all experiments in this article.
Why Qwen 3.5, and Why 2B and 4B?
When we decided to pursue this direction, the release of Qwen3.5 gave us a unique opportunity to compare models across a wide range of sizes within the same family. We designed an experiment across six scales: Qwen3.5-0.8B, Qwen3.5-2B, Qwen3.5-4B, Qwen3.5-9B, Qwen3.6-35B-A3B, and Qwen3.5-122B-A10B.
We used two prompting strategies:
- Bare prompt: Simply ask the model to pick the best candidate from the list. The model outputs only a number.
- Structured Prompt: Provide four reasoning rules (prefer real words, keep brand names intact, consider multiple languages, fewer segments when tied). The model outputs a brief reason, then a number.
The results revealed a striking pattern:
| Model | Bare | Structured | Effect |
|---|---|---|---|
| Qwen3.5-0.8B | 2,335 | 1,906 | -429 |
| Qwen3.5-2B | 3,548 | 4,191 | +643 |
| Qwen3.5-4B | 4,578 | 4,592 | +14 |
| Qwen3.5-9B | 4,641 | 4,546 | -95 |
| Qwen3.6-35B-A3B | 4,731 | 4,531 | -200 |
| Qwen3.5-122B-A10B | 4,771 | 4,609 | -162 |
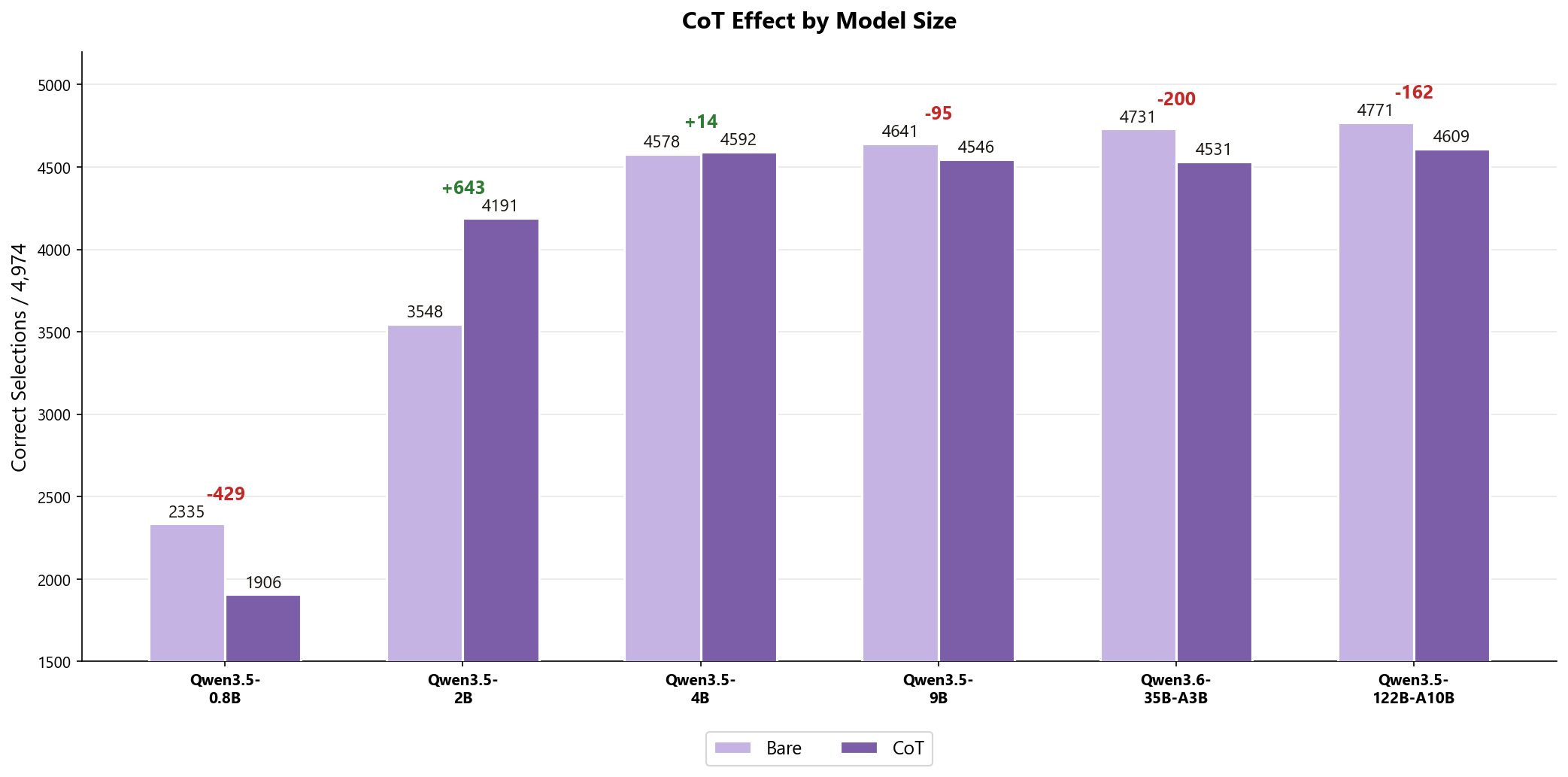
When we saw this chart, we realized that for this simple selection task, the 2B to 4B range was the interval worth studying. Qwen3.5-2B was the only model where the structured prompt produced a massive improvement (+643). For models above Qwen3.5-4B, it was actively harmful. This is the inverted-U: the smallest model could not follow the rules, the larger models were hurt by them on this task, and a sweet spot sat in between.
We confirmed the drop is real: for Qwen3.5-122B-A10B, of its 391 wrong answers, 380 had a clean, parseable choice and only 11 were parsing failures. On this simple task, the larger model does better without the extra rules.
What Happens When We Train
After multiple rounds of experiments with different data scales, we arrived at a trained model and tested it again on the same benchmark of 5,000 domains. The results were clear:
| Model | Bare (start) | Trained (best) | Gain |
|---|---|---|---|
| Qwen3.5-2B | 3,548 | 4,670 | +1,122 |
| Qwen3.5-4B | 4,578 | 4,648 | +70 |
| Qwen3.5-9B | 4,641 | 4,653 | +12 |
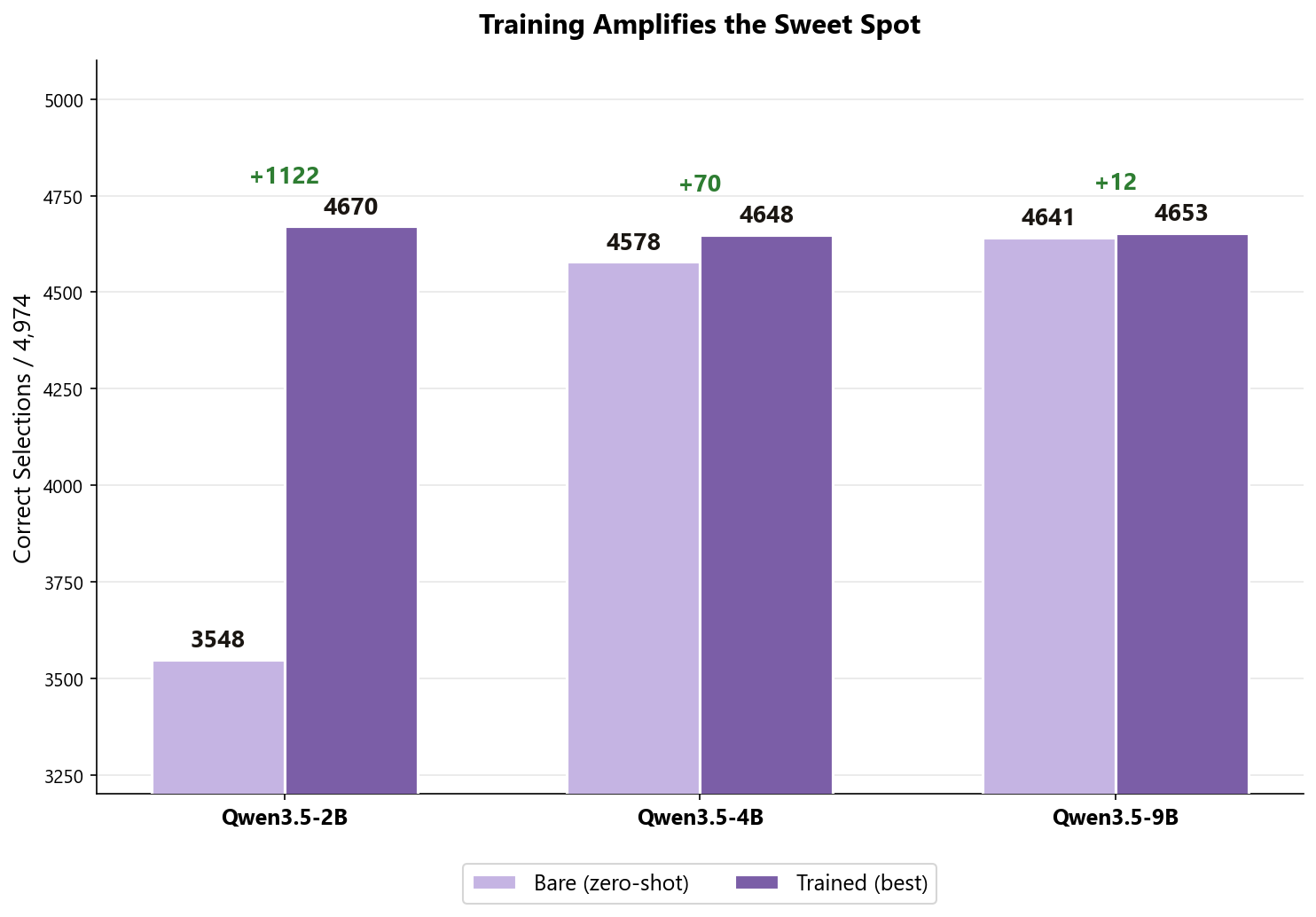
Qwen3.5-2B started as the weakest (3,548) and, after training, caught up with the larger models, landing at 4,670 against Qwen3.5-4B trained (4,648) and Qwen3.5-9B trained (4,653). The three are within roughly 20 samples of each other, so we would not over-read the ranking. The point is that a 1.9 billion parameter model, trained for a few hours on 2 GPUs, reached the same level as models several times its size, at a fraction of the inference cost.
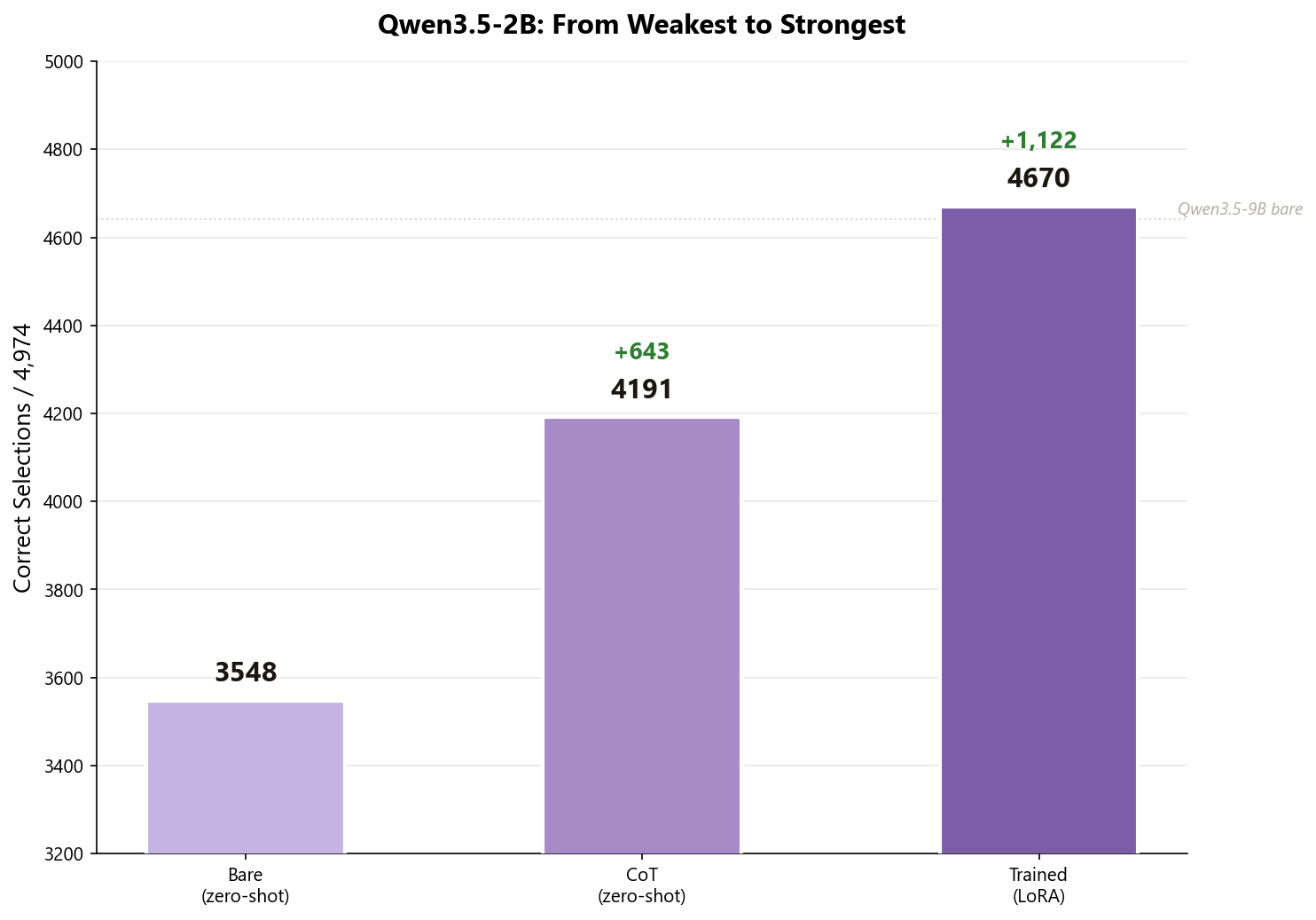
This makes Qwen3.5-2B the sweet spot for deployment, not because it is the single strongest model (the top three are too close to rank), but because training lets it match models several times its size while staying small, fast, and cheap to serve. When accuracy is tied, deployment cost decides the winner.
We also verified this with DKSplit alone, using its CRF k-best Viterbi top-3 candidates. The same pattern held: trained Qwen3.5-2B (4,365) and trained Qwen3.5-4B (4,333) stayed neck and neck, with 2B holding its own against the larger model. The gap to our proprietary pipeline (4,670) reflects candidate quality, but the takeaway is the same on both: a trained 2B is enough.
Key Takeaways
For this selection task, a single trained small model may be the best fit for an agentic workflow: cheap enough to run at scale, yet accurate enough to match models several times its size.
- A structured prompt can unlock a small model’s ability. The right set of rules turned Qwen3.5-2B from the weakest selector into one that competes with the largest, while the same rules added little or even hurt the bigger models.
- Candidate quality and coverage may matter most. The selector can only choose from what the pipeline gives it. The gap between DKSplit top-3 and our proprietary top-5 shows that improving the candidate set lifts final accuracy at least as much as changing the model.
Two Open Questions
Is this the final result?
No, and it should not be. After multiple rounds of comparison, we are fairly confident that Qwen3.5-2B is a strong choice for this selection task, but this is a starting point, not a conclusion. The training data can be refined, the reasoning traces can be made more consistent, and Qwen3.5-9B deserves a fair trial with a data-to-parameter ratio that matches what 2B received. We also want to test across different candidate sets and harder benchmarks. For now, we pause here, with plenty of room left to optimize.
What else does the model know?
While generating training data with LLM APIs, we noticed something more interesting: the models did not just learn to select. They also produced reasonable explanations for their choices, like “Tesamorelin is a well-known pharmaceutical brand name” and “Pflegezentrum is a common, meaningful German compound noun; splitting it is less natural.” Clearly, the models learned more than just picking the best candidate. If we adjust the training angle and the training data, we can leverage the model’s pre-trained knowledge to understand not just how to split a domain, but why it was registered.
Our early tests on that harder task suggest the complexity goes up sharply, and the sweet-spot model is likely to shift with it. That is exactly why finding the engineering sweet spot first, on a well-defined task like this one, makes a good warm-up: it gives us a cheap, repeatable way to calibrate which model size is worth scaling before we take on the harder problem.
DKSplit on EuroHPC Series
- A Two-Week Journey on EuroHPC Leonardo
- DKSplit Update: Cleaner Benchmark, First DeBERTa Run, Different Failure Modes
- Searching for a Teacher Model Across Architectures
- From Domain Segmentation to Reading Domain Signals
- CharBERT and ByT5-CRF
- From Splitting Domains to Picking the Best Split
- Model Selection Through Structured Prompting (this post)
Models tested on a 5,000-sample multi-method audited benchmark (), which does not fully cover all real-world scenarios. Lenient EM accepts matches against truth or might_right. NET = rescue – damage, where rescue means the selector corrects a BiLSTM error and damage means it introduces one. All counts are on the full 5,000-sample set unless noted. This is an engineering evaluation. See our for benchmark methodology.
This work uses models from the Qwen 3.5 and Qwen 3.6 families (Qwen Team, Alibaba Cloud, Apache 2.0), Gemma 4 (Google, Apache 2.0), DeBERTa-V3 (Microsoft, MIT), CharBERT (El Boukkouri et al., Apache 2.0), CANINE (Google, Apache 2.0), and ByT5 (Google Research, Apache 2.0). Training data scoring used DeepSeek V4 Flash (DeepSeek), Gemini 3.1 Flash Lite (Google), and Claude Sonnet 4.6 and Claude Opus 4.6 (Anthropic).

We acknowledge the European High Performance Computing Joint Undertaking (EuroHPC JU) for awarding this project (EHPC-AIF-2026PG01-281) access to the Leonardo supercomputer, hosted by CINECA in Italy.
Co-funded by the European Union. Views and opinions expressed are those of the authors only and do not necessarily reflect those of the European Union or the European High Performance Computing Joint Undertaking.